Understanding RAG: A Practical Guide for Engineers - Part 1: What is RAG and Why Should You Care?

RAG has quietly become the foundational pattern behind almost every AI application that’s actually in production. Not the research demos or the Twitter threads - the things companies are shipping and charging money for.
Customer support systems that answer questions from your docs. Internal search that actually understands what you’re asking. Code assistants that know about your codebase. Document Q&A that doesn’t hallucinate your company’s financials. All RAG underneath.
I’ve spent the last several months building a production RAG system, which meant reading everything I could find on the subject and learning what the tutorials leave out. This series is what I wish existed when I started - a practical explanation of how RAG works, what actually matters, and what questions to ask when you’re evaluating systems or building your own.
The Problem RAG Solves
Large Language Models are impressive, but they have three limitations that matter for real applications:
They’re frozen in time. Every LLM has a knowledge cutoff. GPT-4 doesn’t know what happened last week. Claude doesn’t know what happened last month. They only know what was in the training data, which could be a year or more out of date.
This matters less for “explain quantum computing” and more for “what’s our current refund policy” or “what did the CEO say in last week’s all-hands.” The questions people actually want to ask are often about recent information.
They hallucinate with confidence. When an LLM doesn’t know something, it rarely says “I don’t know.” It generates something plausible-sounding instead. Ask for your company’s Q3 revenue and you might get a number that looks right but is completely fabricated.
For casual use this is annoying. For anything where accuracy matters - legal, financial, medical, customer-facing - it’s a liability. You can’t deploy a system that confidently makes things up.
They can’t see your data. Your internal documents, your codebase, your support tickets, your product specs - none of that was in the training data. The LLM has no idea any of it exists.
This is the fundamental gap. The questions worth answering are usually about your specific context, and the LLM has no access to that context.
What RAG Actually Does
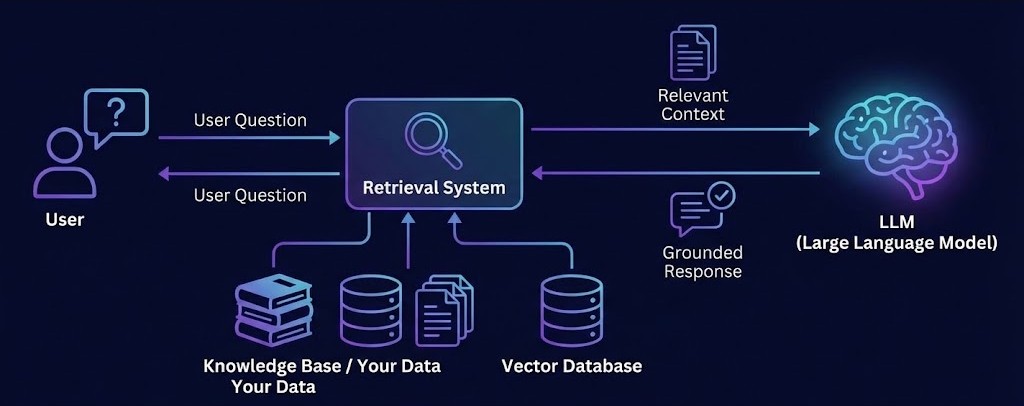
Retrieval-Augmented Generation is a technique that addresses all three problems by combining search with generation:
- Retrieval: When a user asks a question, search a database you control for relevant information
- Generation: Give that information to the LLM as context, then have it generate a response
The LLM isn’t learning anything new. You’re just giving it the right information before asking it to respond.
Without RAG:
User: "What was our Q3 revenue?"
LLM: "I don't have access to your company's financial data."
(or worse: makes up a plausible number)
With RAG:
User: "What was our Q3 revenue?"
↓
System searches your documents → Finds: "Q3 2024 Revenue: $2.3M"
↓
LLM receives: "Based on this context: 'Q3 2024 Revenue: $2.3M'
Answer: What was our Q3 revenue?"
↓
LLM: "Q3 revenue was $2.3M."The difference between asking someone to answer from memory versus letting them check their notes first.
Up-to-date: When your documents change, the answers change. No retraining.
Grounded: Responses are based on retrieved facts, not fabricated from training data.
Your data: Works with whatever documents you have - internal wikis, PDFs, support tickets, code.
Transparent: You can show users which documents the answer came from. Critical for trust.
Why RAG Instead of Fine-Tuning
The obvious question: why not just train the model on your data?
You could. Fine-tuning is a real option. But the tradeoffs usually favor RAG for most business applications:
| RAG | Fine-tuning | |
|---|---|---|
| Updating data | Change your documents anytime | Requires retraining ($$$, time) |
| Transparency | Can cite sources | Black box |
| Cost per query | ~$0.0001 | Same, but high upfront cost |
| Upfront cost | Low | $10k-$100k+ |
| Best for | Facts, documents, current info | Behavior, style, specialized reasoning |
Fine-tuning changes how the model responds. RAG changes what information it has access to.
For customer support, internal knowledge bases, document Q&A, compliance checking - you need current, accurate, citable facts. That’s RAG’s strength.
Fine-tuning makes sense when you need the model to behave differently - adopt a specific tone, follow particular reasoning patterns, or handle specialized domains where the base model struggles. But for “answer questions using our documents,” RAG is almost always the right starting point.
Where You’re Already Seeing This
RAG isn’t theoretical. It’s the architecture behind most AI features that have actually shipped:
Customer support automation - The chatbot that answers questions about your product isn’t relying on the LLM’s training data. It’s searching your help docs, knowledge base, and support articles, then using the LLM to synthesize a natural response. When you update an article, the bot’s answers update immediately.
Internal knowledge search - “Conversational Google for your company” - the ability to ask questions about engineering wikis, design docs, runbooks, and get actual answers instead of a list of links. Slack’s AI features, Notion AI, Glean, dozens of startups - all RAG implementations.
Code assistants - GitHub Copilot’s workspace features, Cursor’s codebase chat, Sourcegraph’s Cody. They’re not just using the LLM’s knowledge of programming - they’re searching your actual codebase and using retrieved code as context. That’s why they can answer questions about your specific implementation.
Document Q&A products - ChatPDF and its many competitors. Upload a document, ask questions about it. The document gets chunked, embedded, stored, and retrieved when you ask questions. Basic RAG in a consumer wrapper.
Enterprise search - The pitch for most “AI for enterprise” vendors. Connect your data sources, ask questions in natural language, get answers with citations. The differentiation is in the connectors, the chunking strategies, the retrieval quality - but the core pattern is RAG.
The pattern is everywhere because it solves a real problem: how do you give an LLM access to specific, current information without retraining it?
The Gap Between Demo and Production
Here’s what the vendor demos and tutorials don’t emphasize: basic RAG is easy to build and disappointing to use.
You can have a working prototype in an afternoon. Split documents into chunks, generate embeddings, store them in a vector database, retrieve similar chunks when someone asks a question, send them to an LLM. Dozens of tutorials will walk you through it.
The problem is that naive RAG - the version you build in an afternoon - typically gets maybe 60% of questions right. That sounds okay until you use it. Users ask a question, get a wrong or incomplete answer, lose trust in the system, and stop using it.
The gap between 60% and 90% accuracy is where most of the actual work lives. Chunking strategies. Hybrid search. Reranking. Metadata filtering. Evaluation frameworks. All the things that turn a demo into something users trust.
That’s what the rest of this series covers.
What’s Coming Next
Part 2: Vectors, Embeddings, and How RAG Actually Works The mechanical explanation - what vectors are, how embeddings capture meaning, how semantic search works. The technical foundation you need to understand why certain decisions matter.
Part 3: RAG in Production - What Actually Matters Hybrid search, chunking strategies, evaluation metrics, data freshness, cost modeling. The production concerns that separate demos from systems people rely on.
I’m building Stache, an open-source RAG platform, and writing this series to share what I’ve learned. Connect on LinkedIn or check out the project on GitHub.